
Googlebot – Wie Google Ihre Website crawlt

WEBneo Blogbeitrag
Das Internet ist gefüllt mit Informationen in einer gigantischen Anzahl von Webseiten. Startet ein User eine Suchanfrage in einer Suchmaschine wie Google, wird eine Liste mit relevanten Ergebnissen generiert und dem Nutzer zur Verfügung gestellt. Suchmaschinen verfolgen das Ziel, ihren Nutzern möglichst exakt zur Anfrage passende Suchergebnisse aus der Vielzahl von Informationen herauszufiltern und bereitzustellen. Suchmaschinen nutzen hierfür sogenannte Website-Crawler wie den sogenannten „Googlebot“. Diese Webseiten-Crawler durchsuchen, einem algorithmischen System folgend, neue und aktualisierte Webseiten und erfassen die gefundenen Inhalte im Index. Auf diese Weise werden täglich Milliarden von Webseiten gecrawlt und zum Google Index hinzugefügt.

WIE FUNKTIONIERT DER GOOGLE BOT?
WIE ARBEITEN SUCHMASCHINEN-CRAWLER WIE DER GOOGLE BOT?
Der Begriff Googlebot setzt sich zusammen aus dem Namen der Suchmaschine „Google“ und der Bezeichnung „Bot“ für ein automatisiertes Programm. Der Google Bot wird häufig auch als „Spider„, „Web-Crawler“ oder „Search-Bot“ bezeichnet. Darunter zu verstehen ist ein Computerprogramm, welches neue Inhalte bzw. neue und aktualisierte Webseiten im Netz besucht, analysiert und anhand der generierten Informationen für Nutzer von Suchmaschinen auffindbar macht. Der Bot durchsucht, einem algorithmischen System folgend, Seiten im Internet und meldet die Ergebnisse an Google zurück, um sie im Suchindex abzulegen. Der Googlebot durchsucht die Seiten, indem er sich von Hyperlink zu Hyperlink in jeder neuen Webseite fortbewegt und dabei alle identifizierten Inhalte herunterlädt und in einer massiven Datenbank sammelt. Diese Datenbank ist der „Google Index“.
Der Prozess der Ermittlung neuer und aktualisierter Webseiten durch den Googlebot wird als „crawling“ bezeichnet. Wie häufig der Googlebot eine bestimmte Seite crawlt, hängt von einer Vielzahl von Faktoren ab. Der Page Rank und die Backlink-Qualität und -Quantität, sowie die Ladezeiten und die Struktur einer Webseite sind unter anderem für die Zeitspanne entscheidend, in der der Google-Bot diese wieder besucht. Einen generellen Richtwert für die Besuchshäufigkeit des Google Bot auf Webseiten gibt es allerdings nicht. Dennoch existieren Faktoren, die diese Häufigkeit positv oder negativ beeinflussen können (hierzu später mehr). Hat der Google Bot eine Webseite gecrawlt, sind die Inhalte der Seite im Google Index erfasst und werden bei entsprechender Themenrelevanz zur Suchanfrage bei den SERPS (Search Engine Result Pages) ausgegeben. Der Nutzer selbst entscheidet anhand der angezeigten Suchtreffer, welche der Ergebnisse für ihn relevant sind.

Der Crawling-Prozess in Google beginnt mit einer Auflistung von Webseiten, die in früheren Crawling-Durchläufen generiert wurden. Als erstes werden alle Einzeldokumente dieser Website gecrawlt. Diese Dateien werden dem Bot bereitgestellt um darüber zu verfügen, welche Inhalte der Webseite indexiert werden sollen und welche ignoriert werden können. Alle Google-Bots folgen bestimmten festgelegten Algorithmen. Glücklicherweise arbeiten die Crawler der größten Suchmaschinen wie Google oder Bing nach vorwiegend gleichen Standards. Im Anschluss daran wird der Content der Seite indexiert. Im dritten Schritt werden alle Links der Webseiten verfolgt. Kann der Google-Bot eine bereits indexierte Webseite zum späteren Zeitpunkt nicht auffinden, so wird diese eventuell vom Index gelöscht. Einige Crawler kehren auch zu einem späteren Zeitpunkt zurück zum nicht gefundenen Linkziel um zu prüfen, ob die Seite tatsächlich offline ist.
WELCHE SEITEN WERDEN GECRAWLT?
WELCHE SEITEN WERDEN VOM GOOGLE BOT GECRAWLT?
Welche Seiten gecrawlt werden, hängt unter anderem von der Anzahl der enthaltenen Backlinks und der internen Verlinkungen ab. Die Anzahl der Seiten die durch den Googlebot gecrawlt werden können, wird durch das jeweilige „Crawl Budget“ der Domain bestimmt. Jede Domain verfügt über ein individuelles Budget, welches die Dauer festlegt, die der Googlebot auf der Seite verbleibt. Neben dem Crawl-Budget verfügen URLs auch über ein Index-Budget. Dieses Index-Budget bestimmt, wieviele URLs von einer Domain im Google Index aufgenommen werden können.

AUSSCHLIEßEN VON INHALTEN IM INDEX
WIE KÖNNEN INHALTE VON DER INDEXIERUNG BEI GOOGLE AUSGESCHLOSSEN WERDEN?
Weist eine Seite sehr viele URLs auf, ist es daher im Rahmen der Crawl-Optimization sinnvoll, irrelevante Webseiten vom Index auszuschließen. Eine Möglichkeit um Seiten gezielt von der Indexierung auszuschließen, ist folgender Befehl im HTML-Header der Webseite:
Mit dieser Eingabe im Header sagen Sie dem Googlebot, dass Sie die aktuelle Webseite nicht indexieren möchten, er aber dennoch den Links auf der Seite folgen soll. Für WordPress existieren einige Plugins, die es ermöglichen, bestimmte Seiten mit dem Meta-Tag „noindex“ zu belegen. Google bekommt dann das Signal, dass diese Seiten nicht indexiert werden sollen. Der Meta-Tag „noindex“ hindert den Googlebot zwar an der Indexierung, jedoch nicht daran, die enthaltenen Links zu crawlen. Möchte man auch dies auszuschließen, öffnen Sie die robots.txt Datei und geben Sie beispielsweise für die Seite „Allgemeine Geschäftsbedingungen“ ein:
Wenn Sie eine .xml Sitemap verwenden, sollten Sie die entsprechenden Seiten, die durch den Googlebot nicht im Index der Suchmaschine aufgenommen werden sollen, aus der Sitemap entfernen. Möchten Sie nicht die gesamte Webseite, sondern lediglich bestimmte Verzeichnisse innerhalb der Seite vom Zugriff durch den Googlebot ausschließen, lautet der Text in der robots.txt beispielsweise:
Die genannten Code-Beispiele beziehen sich auf den Googlebot. Andere Suchmaschinencrawler werden dabei nicht ausgeschlossen.
<meta name=“robots“ content=“noindex, follow“ />
User-agent: Googlebot
Disallow:/AGB
User-agent: Googlebot
Disallow: /name des Ordners/
Disallow: /name-datei.pdf
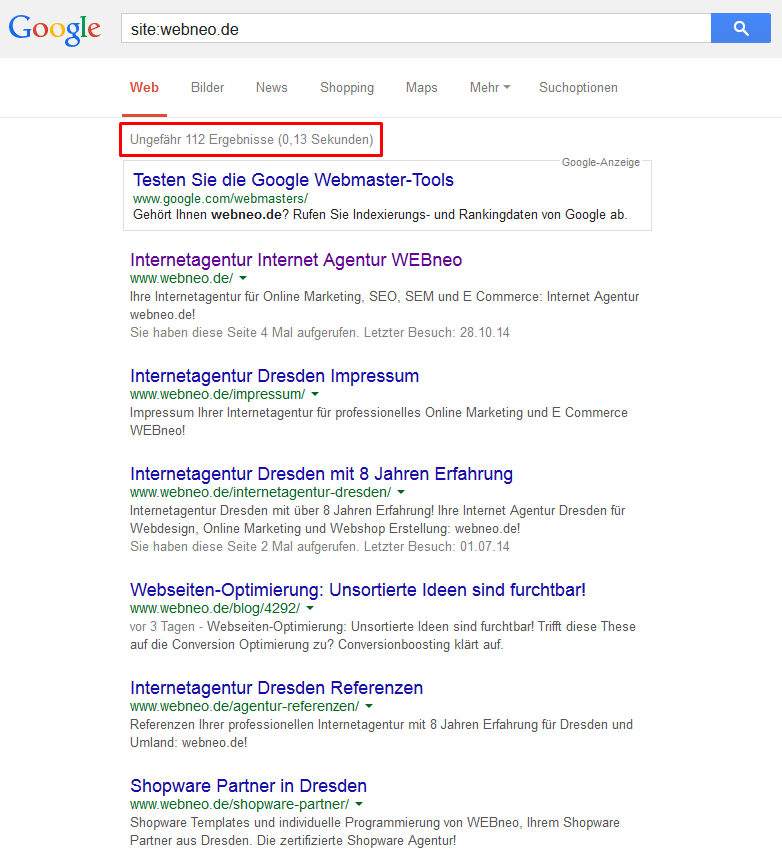
Google-Site-Search
GOOGLE SITE SEARCH
WIE KANN ICH HERAUSFINDEN, WELCHE SEITEN INDEXIERT WURDEN?
Um zu ermitteln, welche Seiten durch den Googlebot im Google Index erfasst worden sind, können Sie entweder eine einfache Suchabfrage mit dem Site-Operator und Ihrer Domain starten. Hier lässt sich die Anzahl der indexierten Seiten ermitteln. Um den Site-Operator anzuwenden, geben Sie in die Google-Suchmaske folgendes ein: site:name-der-domain.com. Die Anzahl der indexierten Seiten werden Ihnen daraufhin angezeigt. Werden viele indexierte Seiten in Google ausgewiesen, lässt sich das Erbebnis der Abfrage weiter filtern.
Die zweite Möglichkeit zur Ermittlung der durch den Google Bot indexierten Webseiten Ihrer Domain ist der Dialog innerhalb der Google-Webmaster-Tools / GWT (Neu: Google Search Console). In den GWT können Sie ganz einfach einen Überblick über die indexierten Webseiten erhalten und den Status der Indexierung analysieren. In einer übersichtlichen Grafik erhalten Sie hier Einblick darüber, wieviele URLs Ihrer Domain zum Google Index hinzugefügt wurden. Darüber hinaus können Sie filtern, auf welche URLs der Googlebot nicht zugreifen konnte, da diese durch die robots.txt Datei blockiert wurden.
Der Sistrix-Sichtbarkeitsindex ist eine weitere Möglichkeit, einen Überblick über indexierte Seiten Ihrer Domain zu erhalten. Im SEO-Modul der Toolbox von Sistrix können Sie die Anzahl indexierter URLs für jede beliebige Domain analysieren. Hierbei können sie zwischen dem historischen Verlauf (Überblick der vergangenen fünf Monate) und dem aktuellen Verlauf wählen.
BESCHLEUNIGUNG DER INDEXIERUNG
MÖGLICHKEITEN, DIE INDEXIERUNG ZU BEEINFLUSSEN
Um die Indexierung Ihrer Webinhalte zu beschleunigen, sollten Sie zunächst für einen nachhaltigen Linkaufbau sorgen. Regelmäßig aktualisierte und thematisch relevante, hochwertige und vor allem einzigartige Inhalte können weiterhin zu einer schnelleren Indexierung beitragen. Die Struktur Ihrer Webseite sollte benutzerfreundlich sein und flache, gut strukturierte Hierarchien aufweisen. Systematische interne Verlinkungen (Seiten pushen, die mehr Linkpower benötigen) können dafür sorgen, dass diese Seiten verstärkt bzw. häufiger gecrawlt werden. Bei internen Verlinkungen sollten Sie darauf achten, dass Sie die Seiten mit der höchsten Relevanz am häufigsten verlinken.


Zu lange Ladezeiten wirken sich negativ auf die Indexierung von Seiten aus. Durch professionelles Webdesign können Sie zu lange Ladezeiten vermeiden. Verringern Sie das Format hochauflösender Abbildungen und sorgen Sie für eine übersichtliche, eindeutige Navigation, damit die Nutzer sich auf Ihrer Seite schnell zurechtfinden (Usabiltiy verbessern). Ein guter PageRank ist ein weiterer maßgeblicher Einflussfaktor für das Crawling von Webseiten. Die Häufigkeit, in der Ihre Webseite vom Googlebot besucht wird, kann durch laufend aktualisierten und neuen Content positiv beeinflusst werden. Je aktueller und relevanter eine Webseite für den Googlebot erscheint, desto häufiger wird die jeweilige Webseite gecrawlt und neue Inhalte indexiert. Besonders für eine schnelle Indexierung von Inhalten ist die Verwendung von „Unique Content“, also einzigartigen Inhalten, die für potentielle Interessenten oder Kunden einen Mehrwert bieten.
Sollten Sie feststellen, dass der Googlebot eine Seite mehrmals herunterlädt, könnte es daran liegen, dass der Crawler beim Download unterbrochen und immer wieder neu gestartet wurde. Im Normalfall lädt der Googlebot jeweils nur ein Exemplar der Websites herunter. Bei neuen Webseiten kann es zwischen einigen Tagen und sogar mehreren Monaten dauern, bis diese indexiert werden. Wenn Sie die genannten Faktoren berücksichtigen, können Sie einer allzu langen Wartezeit entgegenwirken und für eine schnellere Indexierung von neuen Webinhalten sorgen.
Wir hoffen dieser Artikel hat Ihnen geholfen und ein paar interessante Einblicke in die Funktionsweise und Einflussfaktoren von Webcrawlern wie dem Googlebot gegeben. Wir von der WEBneo Online Marketing Agentur freuen uns auf neue Anregungen und Ihr Feedback.
Hier Kontakt zu uns aufnehmen!
Über den Autor